


The Ultra Accelerator Link Consortium has released its 200G v1.0 spec – meaning competition for Nvidia’s BasePOD and SuperPOD GPU server systems from pods containing AMD and Intel GPUs/accelerators is coming closer.
The UALink consortium was set up in May last year to define a high-speed, low-latency interconnect specification for close-range scale-up communications between accelerators and switches in AI pods and clusters. It was incorporated in October 2024 by AMD, Astera Labs, AWS, Cisco, Google, HPE, Intel, Meta, and Microsoft. Alibaba Cloud Computing, Apple and Synopsis joined at board level in January this year. Other contributor-level members include Alphawave Semi, Lenovo, Lightmatter and, possibly, Samsung. We understand there are more than 65 members in total.
The members want to foster an open switch ecosystem for accelerators as an alternative to Nvidia’s proprietary NVLink networking. This v1.0 spec enables 200G per lane scale-up connection for up to a theoretical 1,024 accelerators in a pod. Nvidia’s NVLink supports up to 576 GPUs in a pod.

Kurtis Bowman, UALink Consortium Board Chair and Director, Architecture and Strategy at AMD, stated: “UALink is the only memory semantic solution for scale-up AI optimized for lower power, latency and cost while increasing effective bandwidth. The groundbreaking performance made possible with the UALink 200G 1.0 Specification will revolutionize how Cloud Service Providers, System OEMs, and IP/Silicon Providers approach AI workloads.”
This revolution depends first and foremost on UALink-supporting GPUs and other accelerators from AMD and Intel being used in preference to Nvidia products by enough customers to make a dent in the GPU/accelerator market.
NVLink is used by Nvidia as a near-or close-range link between CPUs and GPUs and between its GPUs. It’s a point-to-point mesh system which can also use an NVSwitch as a central hub.
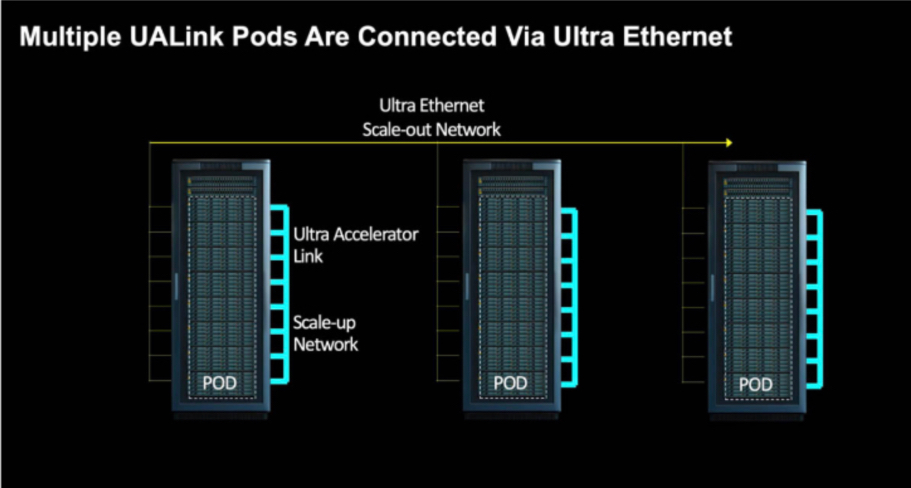
UALink v1.0 provides a per-lane bidirectional data rate of 200 GTps (200 GBps) and allows 4 lanes per accelerator connection, meaning the total connection bandwidth is 800 GBps.
NVLink4.0, the Hopper GPU generation, delivers 900 GBps aggregate bidirectional bandwidth across 18 links, each running at 50 GBps. This is 100 GBps more than UALink v1.0.
NVLink v5.0, as used with Blackwell GPUs, provides 141 GBps per bidirectional link and up to 18 links per GPU connection, meaning a total of 2,538 GBps per connection, more than 3 times higher than UALink v1.0.
NVLink offers higher per-GPU bandwidth by supporting more links (lanes) than UALInk, which can, in theory, scale out to support more GPUs/accelerators than NVLink.
Should Nvidia be worried about UALink? Yes, if UALink encourages customers to use non-Nvidia GPUs. How might it respond? A potential Rubin GPU generation NVLink 6.0 could increase per-link bandwidth to match/exceed UALink’s 200 GBps and also extend scalability out to the 1,024 area. That could be enough to prevent competitive inroads into Nvidia’s customer base, unless its GPUs fall behind those of AMD and Intel.
UALink v1.0 hardware is expected in the 2026/2027 period, with accelerators and GPUs from, for example, AMD and Intel supporting it along with switches from Astera Labs and Broadcom.
You can download an evaluation copy of the UALInk v1.0 spec here.





