


Comment: The big issue for storage suppliers is AI – how to store and make data accessible to AI agents and models. Here’s a look at how they are responding to this.
Using AI in storage management is virtually a no-brainer. It makes storage admins more effective and is becoming essential for cybersecurity. The key challenge is storing AI data so that it’s quickly accessible to models and upcoming agents through an AI data pipeline. Does a supplier of storage hardware or software make special arrangements for this or rely on standard block, file, and object access protocols running across Fibre Channel, Ethernet, and NVMe, with intermediate AI pipeline software selecting and sucking up data from their stores using these protocols?
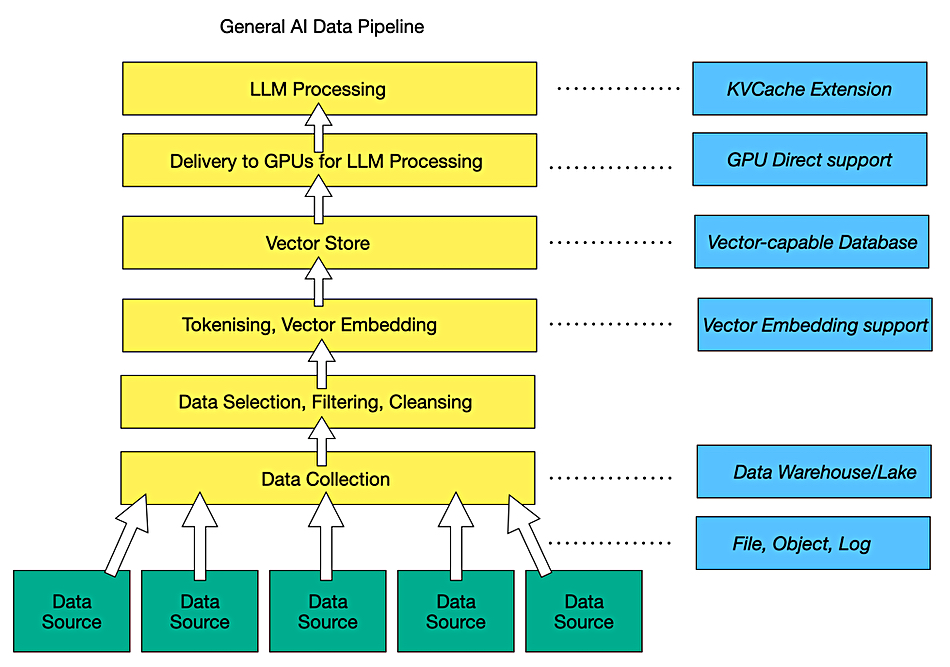
There are degrees of special arrangements for base storage hardware and software suppliers, starting with the adoption of Nvidia GPUDirect support to send raw data to GPUs faster. This was originally limited to files but is now being extended to objects with S3 over RDMA. There is no equivalent to GPUDirect for other GPU or AI accelerator hardware suppliers. At each stage in the pipeline the raw data is progressively transformed into the final data set and format usable by the AI models, which means vector embeddings for the unstructured file and object data.
The data is still stored on disk or SSD drive hardware but the software managing that can change from storage array controller to data base or data lake and to a vector store, either independent or part of a data warehouse, data lake or lakehouse. All this can take place in a public cloud, such as AWS, Azure or GCP, in which case storage suppliers may not be involved. Let’s assume that we’re looking at the on-premises world or at the public cloud with a storage supplier’s software used there and not the native public cloud storage facilities. The data source may be a standard storage supplier’s repository or it may be some kind of streaming data source such as a log-generating system. The collected data lands on a storage supplier’s system or a data base, data lake or data lakehouse. And then it gets manipulated and transformed.
Before a generative AI large language model (LLM) can use unstructured data; file, object or log, it has to be identified, located, selected, and vectorized. The vectors then need to be stored, which can be in a specialized vector database, such as Milvus, Pinecone or Qdrant, or back in the database/lake/lakehouse. All this is in the middle and upper part of the AI pipeline, which takes in the collected raw data, pre-processes it, and delivers it to LLMs.
A base storage supplier can say they store raw data and ship it out using standard protocols – that’s it. This is Qumulo’s stance: no GPUDirect support, and AI – via its NeuralCache – used solely to enhance its own internal operations. (But Qumulo does say it can add GPUDirect support quickly if needed.) Virtually all enterprise-focused raw storage suppliers do support GPUDirect and then have varying amounts of AI pipeline support. VAST Data goes the whole hog and has produced its own AI pipeline with vector support in its database, real-time data ingest feeds to AI models, event handling, and AI agent building and deployment facilities. This is diametrically opposite to Qumulo’s stance. The other storage system suppliers are positioned at different places on the spectrum between the Qumulo and VAST Data extremes.
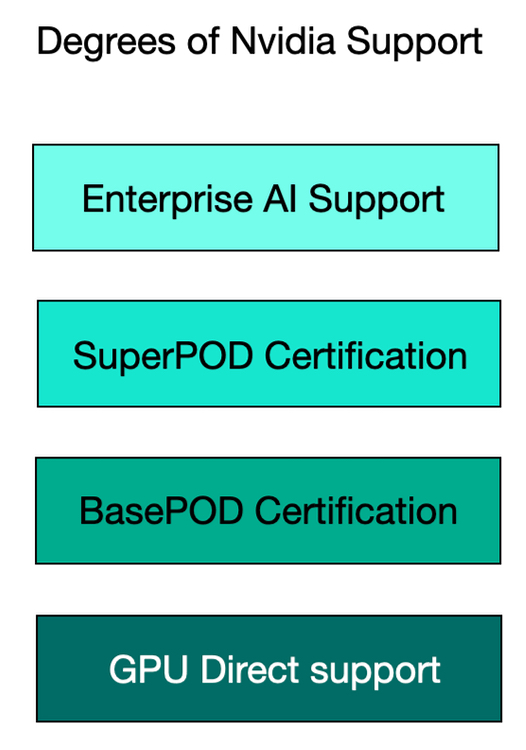
GPUDirect for files and objects is supported by Cloudian, Dell, DDN, Hammerspace, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Pure Storage, Scality, and VAST. The support is not necessarily uniform across all the file and object storage product lines of a multi-product supplier, such as Dell or HPE.
A step up from GPUDirect support is certification for Nvidia’s BasePOD and SuperPOD GPU server systems. Suppliers such as Dell, DDN, Hitachi Vantara, HPE, Huawei, IBM, NetApp, Pure Storage, and VAST have such certifications. Smaller suppliers such as Infinidat, Nexsan, StorONE, and others currently do not hold such certifications.
A step up from that is integration with Nvidia Enterprise AI software with its NIM and NeMo retriever microservices, Llama Nemotron model, and NIXL routines. Dell, DDN, Hitachi Vantara, HPE, NetApp, Pure, and VAST do this.
Another step up from this is to provide a whole data prep and transformation, AI model support, agent development and agentic environment, such as what VAST is doing with its AI OS, with Dell, Hitachi Vantara and HPE positioned to make progress in that direction via partners, with their AI factory developments. No other suppliers appear able to do this as they are missing key components of AI stack infrastructure, which VAST has built and which Dell, Hitachi Vantara and HPE could conceivably develop, at least in part. From a storage industry standpoint, VAST is an outlier in this regard. Whether it will remain alone or eventually attract followers is yet to be answered.
This is all very Nvidia-centric. The three main public clouds have their own accelerators and will ensure fast data access by these to their own storage instances, such as Amazon’s S3 Express API. They all have Nvidia GPUs and know about GPUDirect and should surely be looking to replicate its data access efficiency for their own accelerators.
Moving to a different GPU accommodation tactic might mean looking at KV cache. When an AI model is being executed in a GPU, it stores its tokens and vectors as keys and values in the GPU’s high-bandwidth memory (HBM). This key-value cache is limited in capacity. When it is full and fresh tokens and vectors are being processed, old ones are over-written and, if needed, have to be recomputed, lengthening the model’s response time. Storing evicted KV cache contents in direct-attached storage on the GPU server (tier 0), or in networked, RDMA-accessible external storage (tier 1), means they can be retrieved when needed, shortening the model’s run time.
Such offloading of the Nvidia GPU server’s KV cache is supported by Hammerspace, VAST Data, and WEKA, three parallel file system service suppliers. This seems to be a technique that could be supported by all the other GPUDirect-supporting suppliers. Again, it is Nvidia-specific and this reinforces Nvidia’s position as the overwhelmingly dominant AI model processing hardware and system software supplier.
The cloud file services suppliers – CTERA, Egnyte, Nasuni, and Panzura – all face the need to support AI inference with their data and that means feeding it to edge or central GPU-capable systems with AI data pipelines. Will they support GPUDirect? Will Nvidia develop edge enterprise AI inference software frameworks for them?
The data management and orchestration suppliers such as Arcitecta, Datadobi, Data Dynamics, Diskover, Hammerspace, and Komprise are all getting involved in AI data pipeline work, as selecting, filtering, and moving data is a core competency for them. We haven’t yet seen them partnering with or getting certified by Nvidia as stored data sources for its GPUs. Apart from Hammerspace, they appear to be a sideshow from Nvidia’s point of view, like the cloud file services suppliers.
Returning to the mainstream storage suppliers, all of the accommodations noted above apply to data stored in the supplier’s own storage, but there is also backup data, with access controlled by the backup supplier, and archival data, with access controlled by its supplier. We have written previously about there being three separate AI data pipelines and the logical need for a single pipeline, with backup suppliers positioned well to supply it.
We don’t think storage system suppliers can do much about this. There are numerous backup suppliers and they won’t willingly grant API access to their customer’s data in their backup stores.
If we imagine a large distributed organization, with multiple storage system suppliers, some public cloud storage, some cloud file services systems, some data protection suppliers, an archival vault, and some data management systems as well, then developing a strategy to make all its stored information available to AI models and agents will be exceedingly difficult. We could see such organizations slim down their storage supplier roster to escape from such a trap.





