


Interview: GridGain software enables memory sharing by clustered servers and this means memory-bound applications can run on servers that individually lack sufficient memory. This capability has become increasingly important with AI inferencing as the number of tokens – coded data items – that are required continues to ramp up.
The software provides a distributed memory space across a cluster or grid of x86 servers with a massively parallel architecture. It was donated to the Apache Foundation, becoming Apache Ignite, an open source distributed data management system using server memory as a combined storage and processing in-memory tier, backed up by an SSD/HDD tier. Data is stored using key-value pairs and distributed across the cluster. The software can run on-premises or in the AWS, Azure, and GCP public clouds.
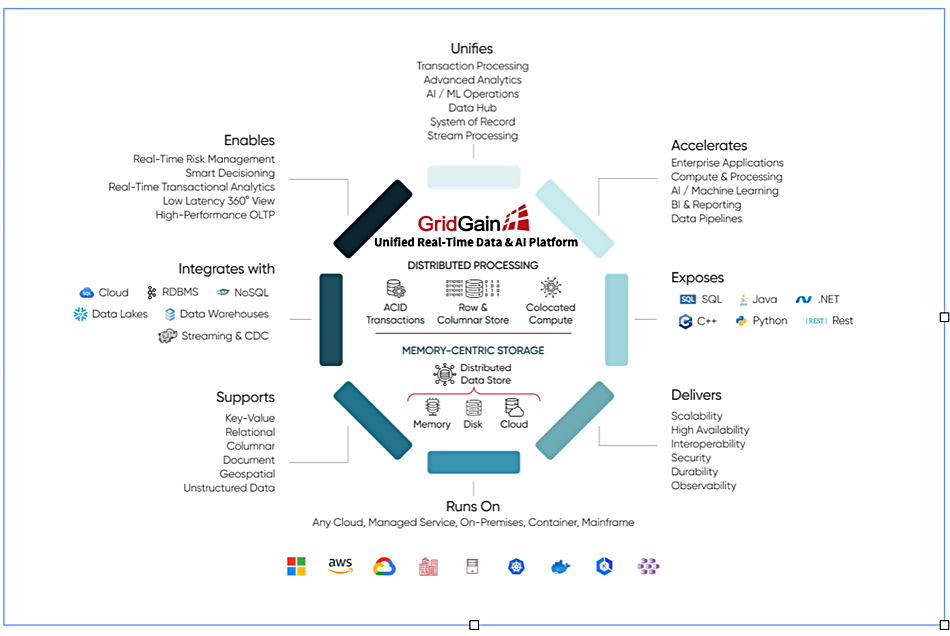
GridGain claims its engine can be used for any data-driven analytical or event processing project, not just AI. It says its software provides an ultra-low latency, distributed, multi-model datastore and a compute engine – combined or colocated with the datastore – that makes data across the enterprise available to the AI inference engine in real time. It also eliminates data movement between the data plane and the compute plane, thus improving efficiency in end-to-end data processing. GridGain has full ANSI 2016 SQL support and provides key-value, row, columnar, document, unstructured, etc., data processing capabilities.

We spoke to CTO Lalit Ahuja to find out more about GridGain’s AI capabilities.
Blocks & Files: Data is stored using key-value pairs and distributed across the cluster. How does GridGain help with AI LLM training?
Lalit Ahuja: GridGain is an ultra-low latency data processing platform that combines the availability of historical/contextual data with the execution of complex analytical and AI workloads to draw inferences in real-time.
GridGain hasn’t yet been used to train LLMs (at least none that we are aware of), but the platform is often used to accelerate the training of AI models, including generation of test data for training purposes or for continuous training, where features can be extracted or vector embeddings generated in real time from incoming transactions and events and made available to the model training exercise, all within GridGain.
Blocks & Files: What has GridGain accomplished in the last 12 months for AI Large Language Model training and inferencing?
Lalit Ahuja: The biggest value proposition of GridGain in the domain of LLMs is its ability to introduce recency into the LLM prompts and RAG applications. By generating vector embeddings on the fly, writing them to its in-memory vector store and making these vectors available to RAG applications, GridGain enables a more accurate, timely, relevant GenAI-based interaction for applications.
For example, in the case of an IVR (Interactive Voice Response) system, a customer’s comment is processed on the fly to generate a very relevant response and a meaningful exchange, thereby minimizing a customer’s request [time] to speak with a human on the other end. Similarly, in corporate communications around incident management, drafting an acceptable message in real time based on incorporating the processing of the latest status of an event or an incident as a prompt to the LLM-based corporate GenAI application.
Blocks & Files: Is GridGain focused on x86 server memory or on GPU (HBM) memory? How do the two use cases differ?
Lalit Ahuja: GridGain is not necessarily focused on one or the other underlying hardware/memory architecture. The platform can work with both these options and relies on the end user to determine where the value is for them. A lot of GridGain customers do not have GPU-based infrastructure and do not see the need to spend on such infrastructure, while others (particularly in banking and, more specifically in the capital markets subdomain) run GridGain on GPUs for improved execution performance for their real-time risk analysis, portfolio management and automated trade execution decisions.
Blocks & Files: Does GridGain have integrations with downstream AI pipeline or storage suppliers to feed it with data to load into memory?
Lalit Ahuja: GridGain does integrate with a number of upstream and downstream AI technologies (including pipeline or storage suppliers), but it also offers a unique ability to its users where it can actually process events and transactions, embellish them with historical, contextual data, extract features, generate vectors and execute any AI workload on this curated data, all in the context of a transaction or an event-driven decision. The underlying ability of GridGain to combine a low-latency, distributed, in-memory data store with a compute engine, all within the same resource pool minimizes the latency introduced by moving data across the network or any form of disk I/O (associated with reading or writing to disk-based stores) and makes such processing more efficient and truly real-time.
Blocks & Files: Is GridGain memory a cache with data ingest and evictions and cache rules for ingest and evictions? How does it work?
Lalit Ahuja: Yes, but it is a lot more. GridGain is (or can be) a cluster of resources (servers, VMs, nodes, pods, etc. deployed simultaneously on-premises, in any cloud or both together) with data distributed in memory across the cluster. This cluster can scale horizontally, within or across data centers.
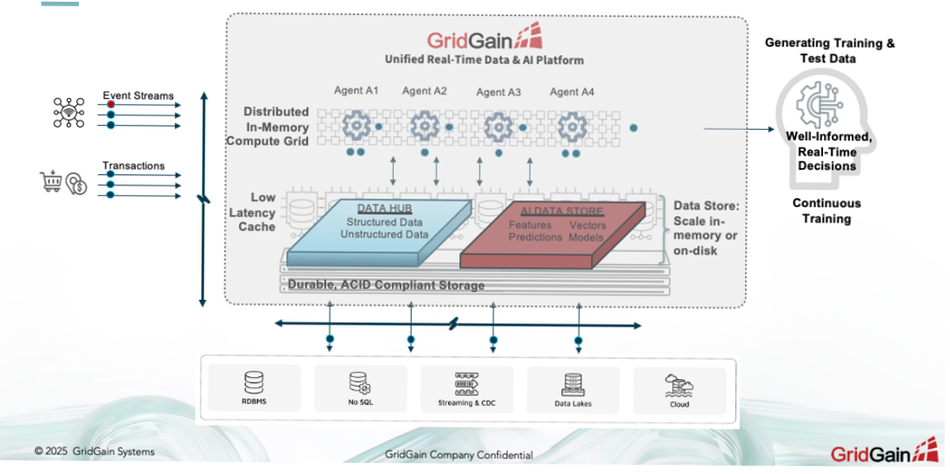
The cluster can be configured to maintain full data integrity, with ACID compliance and zero data loss, with optional durable disk-based stores for backups, snapshots, and point-in-time recovery capabilities. In terms of management of this data, yes, one can configure eviction policies to automatically manage the life of this hot-hot data in memory, with policy-based eviction to GridGain’s own managed disk storage or any third party persistent store.
As far as ingesting data, GridGain exposes a number of standards-based APIs (Java, C++, C#, SQL, REST, Python, etc.) and integrates with several commercial and open-source-based streaming and CDC (Change Data Capture) technologies for data ingestion from all sorts of sources, including RDBMS, NoSQL databases, the mainframe, data warehouses, data lakes – all on-premises or cloud-based.
Blocks & Files: How are clustered server memory contents kept in sync and organised? Are there communications between server memories?
Lalit Ahuja: The data is partitioned across the various memory resources within the cluster, with the option to replicate the data (RF2, RF31 etc.) across the cluster for redundancy, high availability and configurable immediate/strict or eventual consistency. The resources in the cluster constantly communicate with each other; data consistency and cluster organization is managed by robust industry-standard consensus protocols implemented within GridGain.
Blocks & Files: How does GridGain relate to WEKA’s Augmented Memory Grid?
Lalit Ahuja: There is some overlap between GridGain’s AI data store and WEKA’s Augmented Memory Grid. That said, the use cases that a WEKA-like data grid supports versus what GridGain excels at are slightly different. The value of WEKA may be in the economies of scale around reusable AI tokens, whereas GridGain’s differentiator is in its ability to generate such tokens from raw data on the fly and make them available for real-time AI/analytics driven use-cases.
With our core design/feature principles of working with any back-end data store, we have started exploring integrating with the WEKA grid as a source of data for more historical analytical use cases, around trends, patterns, predictions, etc.
Blocks & Files: Does GridGain have an edge AI inferencing use case applicability?
Lalit Ahuja: Yes, as GridGain can run on edge infrastructure – we see uses in telco and IoT related edge computing applications. It can run localized compute/analytics on relevant data delivered to or fed to the edge clusters from localized sensors, devices or event streams, or other connected GridGain clusters – globally deployed GridGain clusters can selectively replicate data amongst each other, with added ability to protect against network segmentation, if that is an issue – across its network.
Blocks & Files: How does GridGain technology relate to that of MemVerge?
Lalit Ahuja: GridGain does not quite directly relate to MemVerge’s technology, but we are constantly evaluating ways to better optimize our processing capabilities and provide economical options to our customers around the underlying resource management.
Blocks & Files: How will CXL affect GridGain?
Lalit Ahuja: CXL is also one of those things that we are looking at to help optimize the utilization of underlying resources. In this case, more so for improving our data replication and availability capabilities.
Bootnote
1RF-2 is Resiliency or Redundancy Factor-2, and means that the data has a single redundant copy in the system. RF-3 means there are two extra copies for increased security against data loss.





