


Interview: We spoke to DDN SVP for Products James Coomer and CTO Sven Oehme about the status of its relatively new Infinia object store and about details on its claimed performance, multi-tenancy, and resilience.
Blocks & Files: What’s the status of Infinia?

James Coomer: We’ve now been in production for quite a while. v2.2 is coming out shortly and it has strong multi-tenancy features with security/resilience, performance and capacity SLAs.
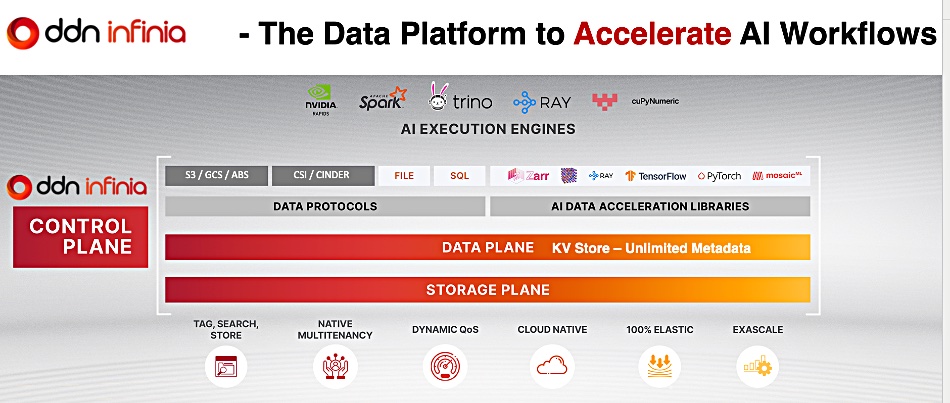
In Infinia’s architecture everything is a key-value store at the base of the system, unlike other systems which may have a block storage base layer, then a file system and then exporters for objects.
By using a key-value store, it allows us to basically distribute all the data in the system equally across all the devices because keys and values are very easily distributable, you can basically spread them across all the devices.
We are using a Beta Epsilon tree data structure, which is a very advanced key-value store essentially that has a nice balance between reads and writes. If you look at previous data structures, either they optimize for reads or they optimize for writes.
That means in Infinia [that] every data source that we provide – it doesn’t matter if this is object, various forms of object, we are going to come out with different data services besides block that we already support – everything is a peer to each other. Instead of layering things on top of each other, everything is a peer.
Blocks & Files: How about its performance?
James Coomer: We’ve traditionally been very strong for throughputs, obviously, and IOPS and single threaded throughput; those are all very important and still are in the world of AI. But with Infinia we’re also concentrating on the other end of the spectrum, which is listing performance: time to first byte and latency. Listing performance is when you have a million things in a bucket. I want to find all of those objects which are images with pictures of cats.
That’s like the stereotypical requirement inside a RAG query. You run your RAG query and it’s got to search a massive knowledge base and find things relevant within a fraction of a second. What you need is a storage environment, a data platform, which is going to allow you to search, list and retrieve, not just do IOPS and not just do throughput. You’ve got to find it first. And finding things first is like the new challenge of AI. It’s how quickly can I find this data, which is millions or even hundreds of millions of objects.

Sven Oehme: When you look at AWS and a lot of the other objects stores, what they basically do is they put all of those things in a database on the site. Even if you don’t see that, there is something running in the background that is basically typically an in-memory database to do some of these things. Still, despite that, they have not been able to actually make this really fast.
With Infinia this is actually a property of the way we lay out the data structures in the key-value store because, with the key-value store, we can actually auto index, prefix and load balance all the objects that are created – because it is a one-to-one mapping between the object name and the key value in the key-value store.
That allows us to basically do things like prefix rendering and also prefix prefetching. And so when you run an object listing on AWS, you get about 6,000 objects per second if you’re really lucky, maybe 10,000 per second. We’ve demonstrated in production at one of our first customer object listing with a single thread of over 80,000 per second. Where we use multiple threads, which doesn’t actually scale on AWS because they have no way to actually parallelize the listing, we were able to, on that same data set, improve this to 600,000 per second. So we are basically about 100 x faster than AWS in object listing. It doesn’t stop there. If you actually run this across multiple buckets, in parallel on one of our systems in production, we are able to do 30 million objects per second listing across multiple buckets.
Blocks & Files: And latency?
Sven Oehme: If you look at latency, the time to first byte, [then] when you go to AWS S3, your latency is about a hundred milliseconds per request. If you go to a S3 Express, which is about 12 times more expensive than S3, you get about a 10 millisecond response time. If you deploy Infinia in AWS on AWS VMs, your latency is about a millisecond.
Basically from S3, through S3 Express to Infinia there is a 100x improvement in latency, while Infinia actually has a lower cost point running on AWS than AWS S3 Express itself.
Now, when we are talking about [a] put and get operation in a millisecond or less, you are in file system latency territory. You can basically now run very interactive workloads on an object store that before you could only run on file systems.
What we believe is we are going to have a very low latency object store implementation that allows you to do distributed training in lots of different sites, maintaining very low latency compared to a file system, but in a distributed way like an object store can operate.
James Coomer: We’ve kind of got Stockholm syndrome when it comes to POSIX and file. We think we love it, but we only love it because we’ve been beaten up and punished by it for 20-plus years. And actually if you stand outside the circle and look at it, it’s awful. POSIX is terrible in today’s world with massive aggregated access, distributed data, huge amounts of metadata. It does nothing well and object does everything well, apart from latency and that single-threaded throughput. And those are the challenges we’ve been able to solve.
Blocks & Files: Tell me about Infinia’s multi-tenancy
James Coomer: When incoming requests come in, we can take a look at, okay, what tenant is it? What subtenant? And then we can completely distribute this [data] across all the available resources. While if you take the traditional approach, typically people have volumes and volumes that are assigned to a particular tenant. So there is a direct linkage between capacity, performance and a consumer. While in our system there is no linkage.
[This] means we can do crazy stuff like you get 99 percent of the performance but you only get 1 percent of the capacity or you only get 1 percent of performance, but you get 99 percent of capacity.
These are extremes that you can’t do on legacy systems because it’s basically more resource allocation than SLA-based management. We can really, truly do SLA-based management on performance, on capacity, and also very importantly, on resilience.

You can say this particular set of data I’m storing here for this particular tenant, it’s so critical it needs to survive site failures. But these other data sets over here, they’re not critical. I want to get the highest performance, so therefore they should be locally stored wherever that data and consumer resides.
Being able to dial this in on every single data service [and] in one gigantic shared infrastructure is something that is very, very unique.
Blocks & Files: Tell me about Infinia’s resilience
Sven Oehme: We talk basically resilience in the form of how many failures can we survive? And if you have a small system that is all in one rack, the only things it can really survive are nodes and drives. But if you deploy an Infinia system across physical sites, [say] five physical sites, you can define a data set that is so critical, it needs to survive a site failure.
Then we automatically either apply erasure coding that is wide enough to cover the site failure or we dynamically apply replication. And that depends on the size of the IO you do and what is more efficient from a resilience versus capacity planning point of view. But the system does this all automatically. So all the end user does is apply an SLA for resilience and then the system automatically takes care of how that protection can be handled in the most efficient way.
Blocks & Files: How does Infinia treat SLAs?
James Coomer: When it comes to multi-tenancy, typically people want a service level which defines a minimum service, right? They’re never going to get less than X, Y or Z. And it seems to me what everybody else has done is basically implemented something that’s quite crude, which is a maximum. Which is kind of the opposite of what people are asking for. They want to know that applications are never going to be experiencing a downfall in performance because they’re getting interactions with other tenants. What they don’t want is to be limited to an artificial ceiling when there’s lots of resources available.
Sven Oehme: Our implementation of quality of service actually assigns priorities amongst the tenants and then within the tenants amongst their subtenants and individual data services. So that means if you’re not using your share in some of these other peer neighbours, you can take full advantage of the system, but as soon as your peer neighbours within that same quality of service as a group and start using their parts, everybody gets assigned into their fair share lane, which means if you have multiple medium priority, a bunch of low and one high priority workload, if that high priority workload doesn’t run, everybody else can use the full set of performance of the system.
As soon as the high priority workload comes in, it gets the maximum share possible and everybody else still doesn’t get stalled out, but they get the appropriate value to it. And so basically we have a notion of up to 64 individual levels of quality of service priority. We don’t expose them to the end user because it’s typically too complex for people to deal with that amount of high granularity. So we provide three preset defaults, which are basically a high priority default, a low priority default and a medium priority default.
The end user could, if they want to, do this through the REST interface or CLI to adjust this, but these are the preset values.
Blocks & Files: DDN is changing its spots a little bit. It’s no longer about just providing the fastest possible parallel storage for HPC and AI sites. It’s developing a software stack.
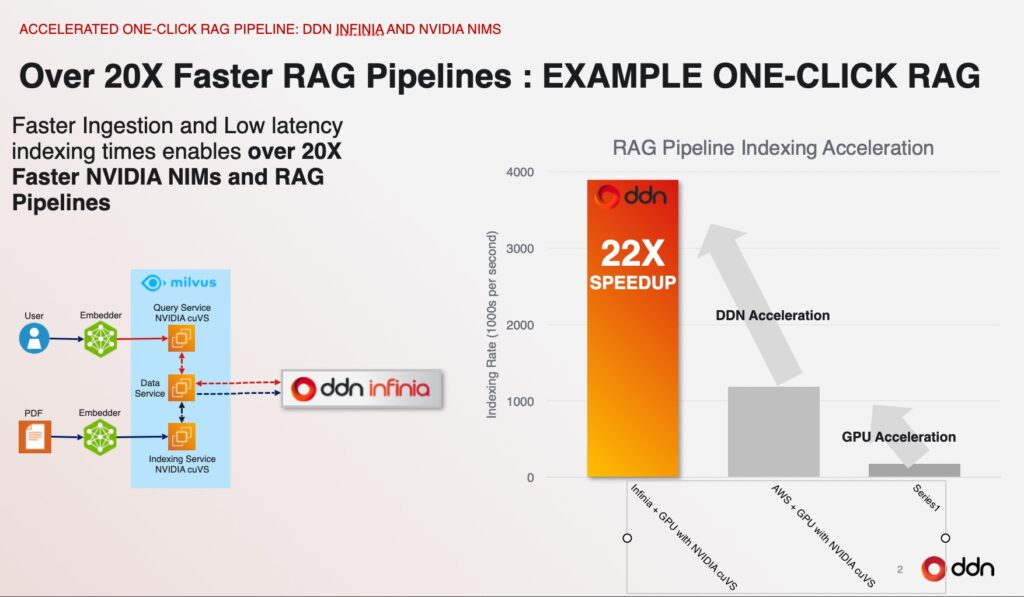
Sven Oehme: Absolutely. And in fact, you see this in a lot of other places. I don’t know if you’ve seen our RAG pipeline demo that we’ve done on AWS. We built an entire end-to-end RAG pipeline. We deployed this on AWS and we used only AWS services for the first version of it. And then what we did is we basically replaced two components. So everything was using just AWS internal services for GPUs for the storage. We used AWS S3 Express and then what we did is we added a highly optimized version of the Milvus database using GPU offloading that we’ve co-developed together with Nvidia. And then we replaced the S3 Express object store with our Infinia object store interface and we were able to speed up that entire RAG pipeline by 22x and we were able to do this while reducing the cost by over 60 percent. You don’t need to run on on-prem super highly-powered hardware.
Blocks & Files: Are there built-in services?
James Coomer: We do data reduction by default. There is not even a knob or any tuning or anything to tweak with it. It’s just on all the time. We encrypt all the data all the time. Also here, there is no knob, there is no tweak you need to do whenever you set up an Infinia system and automatically there is encryption. If there is no hardware acceleration for encryption, we do everything in software. If there is hardware, we take the hardware encryption.
Blocks & Files: Can you discuss your roadmap at all?
James Coomer: There is a lot of work we are doing together with Nvidia right now to integrate in a lot of upcoming features like KV Cache support. There’s upcoming support for GPUDirect for Object. We were a little bit late for that, but there is a very good reason for it because our Infinia software stack provides a software development kit which already did RDMA offloading of data transfers into the system. And given that this is the main feature that is provided by GPUDirect for Object, we are just adding this now.





