


WEKA is turning a set of GPU server’s local SSDs into a unified high-performance storage pool for faster AI training and inferencing data access and system deployments with its NeuralMesh Axon software.
It is doing this by porting NeuralMesh functionality from external scale-out storage servers to the local storage infrastructure inside GPU servers.
NeuralMesh is an external and scale-out, file and object storage architecture for providing resilient and high-performance storage to a bunch of GPU servers. It is a kind of storage fabric, distributing data and metadata across all nodes in a single namespace, balancing I/O dynamically with built-in auto-healing, using erasure-coding, auto-scaling, and fast rebuild capabilities. Here’s a conceptual diagram:
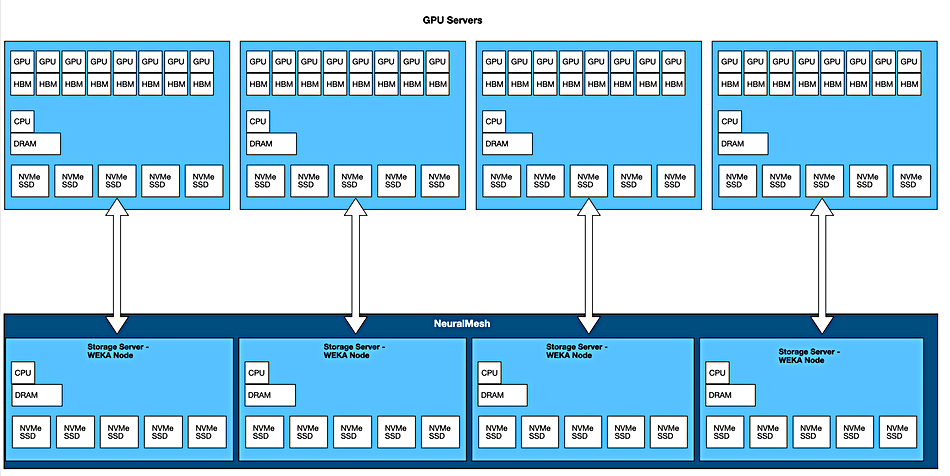
NeuralMesh Axon extends this architecture into the GPU servers, running as containerized software and utilizing their local NVMe SSDs, x86 CPU cores and DRAM, and NICs.
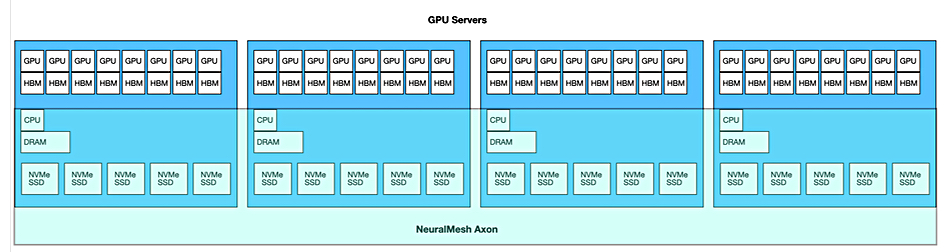
WEKA’s Chief Product Officer Ajay Singh blogs: “This unified, software-defined compute and storage layer significantly improves GPU utilization for training workloads, enhancing the overall economics of the infrastructure stack—particularly compute resources—while delivering superior storage throughput and I/O performance.”

Reads and writes are distributed across GPU nodes for scalable, linear performance.
Singh says: “Complementary capabilities such as Augmented Memory Grid further amplify performance for inference by addressing latency and memory barriers, delivering near-memory speeds for KV cache loads at massive scale. It consistently achieves microsecond latency for both local and remote workloads, outperforming traditional local protocols like NFS.”
It “gives organizations the ability to predefine resource allocation across the existing NVMe drives, CPU cores, and networking resources—transforming isolated disks into a memory-like storage pool for even the largest AI workloads.” Customers can pre-allocate a GPU server’s CPU, memory, NVMe capacity and NICs to guarantee consistent performance and prevent noisy neighbor-type effects.
He says this design copes better when different GPU servers need access to the same data set as it avoids having “multiple full copies of data across servers, which results in substantial capacity overhead while suffering steep performance drops when a node fails.” There is also no need for replication between the GPU servers.
Node failure is acceptable up to four simultaneous failures due to NeuralMesh erasure coding, he says.
WEKA says NeuralMesh Axon “has delivered a 20x improvement in time to first token performance across multiple customer deployments, enabling larger context windows and significantly improved token processing efficiency for inference-intensive workloads. Furthermore, NeuralMesh Axon enables customers to dynamically adjust compute and storage resources and seamlessly supports just-in-time training and just-in-time inference.”
It can support >100 GPU servers and it’s also faster to deploy than GPUs + NeuralMesh or other GPU servers + external storage configurations. NeuralMesh Axon reduces the required rack space, power, and cooling requirements in on-prem data centers, helping to lower infrastructure costs and complexity by using existing server resources.
Nvidia provided a supportive comment, with Marc Hamilton, its VP of solutions architecture and engineering, saying: “By optimizing inference at scale and embedding ultra-low latency NVMe storage close to the GPUs, organizations can unlock more bandwidth and extend the available on-GPU memory for any capacity.” NeuralMesh Axon can: “provide a critical foundation for accelerated inferencing while enabling next-generation AI services with exceptional performance and cost efficiency.”
Autumn Moulder, VP of engineering at AI model developer Cohere, stated: “Embedding WEKA’s NeuralMesh Axon into our GPU servers enabled us to maximize utilization and accelerate every step of our AI pipelines. The performance gains have been game-changing: Inference deployments that used to take five minutes can occur in 15 seconds, with 10 times faster checkpointing.”
CoreWeave CTO and co-founder Peter Salanki said: “With WEKA’s NeuralMesh Axon seamlessly integrated into CoreWeave’s AI cloud infrastructure, we’re bringing processing power directly to data, achieving microsecond latencies that reduce I/O wait time and deliver more than 30 GB/s read, 12 GB/s write, and 1 million IOPS to an individual GPU server.”
Cohere is deploying NeuralMesh Axon on the CoreWeave Cloud after first deploying it in the public cloud.
NeuralMesh Axon supports the main cloud GPU instances as well as on-prem and hybrid deployments. It’s intended for use in 100+ GPU server deployments for enterprise AI factories, Neo cloud providers and any other “LLM or multi-modal model deployments where ultra-low latency, high throughput, and GPU-native storage integration are critical.”
NeuralMesh Axon is currently available in limited release for large-scale enterprise AI and neocloud customers, with general availability scheduled for fall 2025. Read more in a NeuralMesh Axon solution brief document.
Comment
It is worth reading about DDN’s Infinia with its erasure coding, and considering how it compares to WEKA’s NeuralMesh. Hammerspace with its Tier Zero concept uses a GPU server’s local SSDs like WEKA’s new software and is another comparison point.
A third one is that VAST Data can utilize local SSDs inside GPU servers through its VUA (VAST Undivided Attention) KVCache software technology. The GPU server’s SSDs function as a caching tier for AI model training and inferencing tokens.
Bootnote
WEKA notes that, to maximize the performance of NeuralMesh Axon, most environments should leverage the Kubernetes Operator — ideal for cloud and service provider deployments requiring advanced data protection and seamless orchestration. NeuralMesh Axon is optimized for balanced resource use, with around 4 CPU cores per NVMe drive and 100 GB of huge pages per server. Advanced networking (6 InfiniBand NICs for east–west and 2 Ethernet NICs for north–south) ensures backend traffic never disrupts GPU workloads. For large-scale AI factories, enhanced data protection (RAFT9 with +4 parity) and thoughtful failure domain design deliver resilience and efficient updates, while maintaining homogeneous hardware and buffer nodes ensures smooth, reliable operations.





