


Vector buckets have been added to AWS S3 object storage to lower the cost of having infrequently accessed vectors stored in Amazon’s OpenSearch Service.
Unstructured data is being seen as increasingly important to organizations adopting large language model-based AI, with retrieval-augmented generation (RAG) and agents being part of that. RAG brings proprietary information to the LLMs and agents. The bulk of it is unstructured and needs vectorizing so that the LLMs and agents can bring their vector-based analysis to bear. Special LLMs do the vectorizing and then the vectors need storing. AWS is already doing that with its OpenSearch Service. However, it has a disadvantage compared to on-prem object stores and databases that store vectors. An AWS database instance costs in terms of storage capacity and also compute. By storing infrequently accessed vectors in S3, AWS can reduce compute costs for vector databases and save customers money.
Channy Yun, AWS Principal Developer Advocate for AWS cloud, writes in a blog: “We’re announcing the preview of Amazon S3 Vectors, a purpose-built durable vector storage solution that can reduce the total cost of uploading, storing, and querying vectors by up to 90 percent.”
This makes it cost-effective to create and use large vector datasets to improve the memory and context of AI agents as well as semantic search results of customers’ S3 data. The S3 Vectors feature is, an AWS announcement says, “natively integrated with Amazon Bedrock Knowledge Bases so that you can reduce the cost of using large vector datasets for retrieval-augmented generation (RAG). You can also use S3 Vectors with Amazon OpenSearch Service to lower storage costs for infrequent queried vectors, and then quickly move them to OpenSearch as demands increase or to enhance search capabilities.”
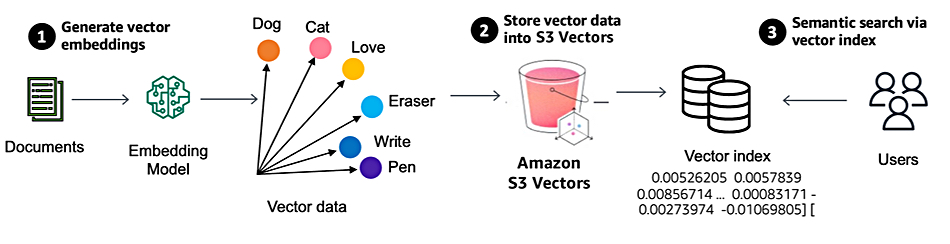
S3 vector support comes via a new vector bucket, which Yun says has “a dedicated set of APIs to store, access, and query vector data without provisioning any infrastructure.” The bucket has two types of content: vectors and a vector index used to organize the vectors. “Each vector bucket can have up to 10,000 vector indexes, and each vector index can hold tens of millions of vectors,” Yun says.
There’s a neat extra twist: “You can also attach metadata as key-value pairs to each vector to filter future queries based on a set of conditions, for example, dates, categories, or user preferences.” This cuts down vector selection and scan time.
S3 Vectors automatically optimizes the vector data to achieve the best possible price-performance for vector storage as bucket contents change.
The S3 Vectors feature is integrated with Amazon Bedrock Knowledge Bases, including within Amazon SageMaker Unified Studio, for building RAG apps. When creating a knowledge base in the Amazon Bedrock console, you can choose the S3 vector bucket as your vector store option.
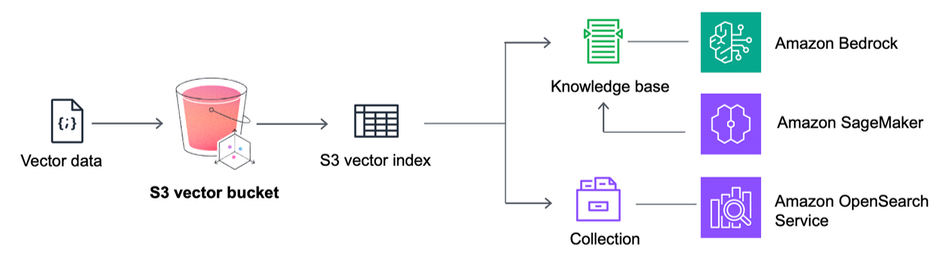
S3 Vectors also has an integration with the Amazon OpenSearch Service. If you do lower storage costs by keeping low access rate vectors in S3 Vectors, you can move them to OpenSearch if needed and get real-time, low-latency search operations.
Andrew Warfield, a VP and Distinguished Storage Engineer at AWS, said: “S3 vectors anchors cost in storage and assumes that query demand fluctuates over time, meaning you don’t need to reserve maximum resources 100 percent of the time. So when we look at cost, we assume you pay for storage most of the time, while paying for query/insertion costs only when you interact with your data.
“When we looked across customer workloads, we found that the vast majority of vector indexes did not need provisioned compute, RAM or SSD 100 percent of the time. For example, running a conventional vector database with a ten million vector data set can cost over $300 per month on a dedicated r7g.2xlarge instance even before vector database management costs, regardless of how many queries it’s serving.
“Hosting that same data set in S3 will cost just over $30 per month with 250 thousand queries and overwriting 50 percent of vectors monthly. For customers who have workloads that heat up, they can also move their vector index up to a traditional vector store like Open Search, paying instance-style cost for the time that the database is running hot.”
Yun’s blog post explains how to set up and use S3 Vectors.
AWS is not alone in adding vector support to object storage. Cloudian extended its HyperStore object storage with vector database support earlier this month, using the Milvus database.
The Amazon S3 Vectors preview is now available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Sydney), and Europe (Frankfurt) Regions. To learn more, visit the product page, S3 pricing page, documentation, and AWS News Blog.





