


Analysis. GPUs are hitting a memory bottleneck as model sizes outpace onboard capacity. Since GPU memory isn’t scaling fast enough to meet demand, companies like Phison and Sandisk are turning to virtual RAM (VRAM) alternatives – Phison via software, and Sandisk with hardware – using NAND flash as a GPU memory cache.
Phison’s aiDAPTIV+ software is quicker to implement than Sandisk’s hardware, speeds up AI model training by avoiding external storage token access, and enables smaller GPUs to take on larger jobs. Sandisk’s High Bandwidth Flash (HBF) promises much higher speed, but will require semiconductor-level hardware and firmware developments for each GPU manufacturer.
As we understand it, the Phison software is middleware that runs on a GPU server, with onboard GPUs and a CPU, and sets up a virtual memory pool spanning the GPU’s own memory, be it normal GDDR or High Bandwidth Memory (HBM), CPU DRAM, and an SSD.
When an AI model is loaded, aiDAPTIV+ analyzes its memory needs and slices the data into component parts that are either hot (placed in GPU memory), warm (assigned to CPU DRAM), or cool (assigned to SSD). The SSD is a fast Phison SLC (1bit/cell) drive such as its AI100E M.2 product.
The per-data slice needs change as the AI model runs and aiDAPTIV+ software moves data between the three virtual memory tiers to keep the GPUs busy and avoid token recomputation.
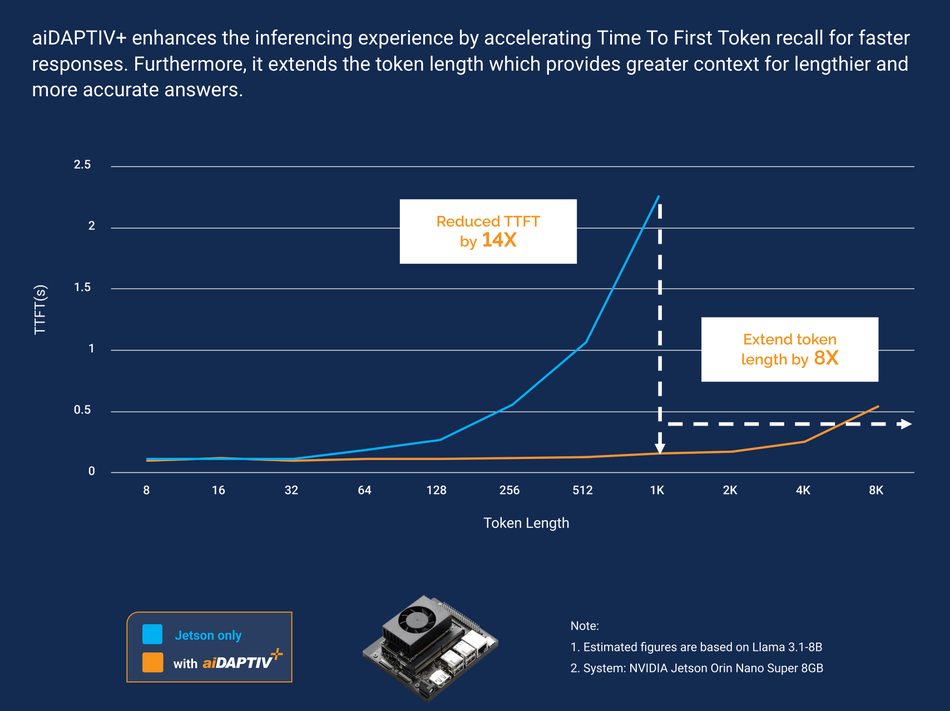
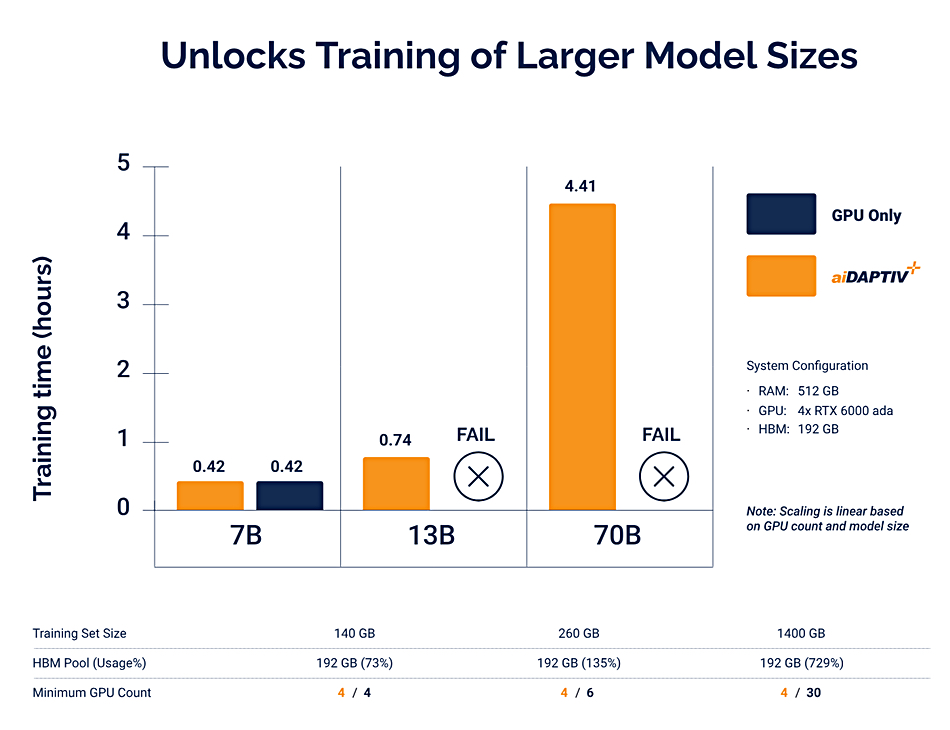
This enables a smaller number of GPUs, with inadequate amounts of their own memory, either HBM or GDDR, for a large model. Phison claims its system can support models with up to 70 billion parameters with a sufficiently large VRAM pool. It means on-prem AI systems can operate larger models for training that would otherwise be impossible or need to be expensively submitted to GPU server farms run by CoreWeave et al. It also means that smaller, less powerful GPUs, and also smaller edge GPU server systems, can run larger inference jobs that would otherwise be infeasible. Think of Nvidia RTX 6000 Ada or Jetson platforms.
There is no standard GPU HBM/GDDR interface and the Phison software has to be deployed in custom engagements with GPU server and system suppliers. This is done so as to achieve data movement across the three VRAM tiers without modifying the AI application (e.g. PyTorch/TensorFlow). System vendors have access to Phison’s AI100E SSD, middleware library licenses, and support to facilitate system integration.
The list of Phison partners includes ADLINK Technology, Advantech, ASUS, Gigabyte, Giga Computing, MAINGEAR, and StorONE.
Phison engineers developed aiDAPTIV+ in-house because it couldn’t cover the expense of a full high-end model training system. CEO K. S. Pua says in a video: “My engineer leaders came to me. They asked me to pay them few million dollars to get the machine to do our in-house training, to lower our loading in the human resource to improve the cycle time, to improve efficiency. But I told them, a few million dollars; I’m not able to afford to pay for it. So they go back to their lab, they start to think how to reduce the barrier. Those are smart people. They found a solution to use Phison proprietary enterprise SSD to make it into the systems making the LM training able to execute.”
Get an aiDAPTIV+ solution brief document here.
Sandisk HBF
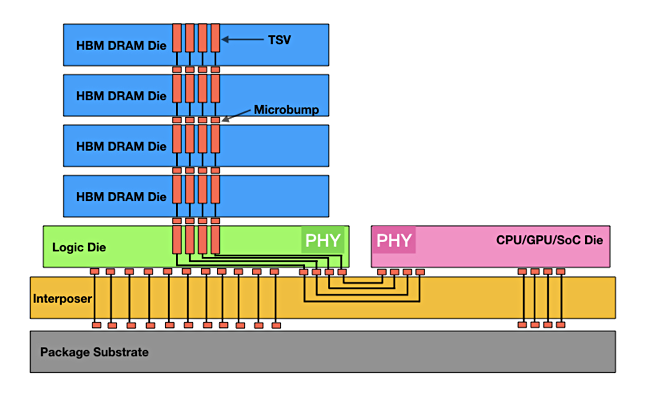
Sandisk’s option requires close co-development with GPU suppliers because it is built like HBM. This has DRAM die stacks layered above a logic die and connected to it by Through Silicon Via (TSV) connectors. The combined stack is itself connected to a specially designed interposer component that links it to a GPU:
HBF uses the same architecture, with a stacked layer of NAND dies connected by TSVs to a bottom logic layer. This is affixed to an interposer and so connected to a GPU. But it isn’t that simple. HBF augments HBM. So the GPU already has an interposer connecting it to an HBM stack. Now we have to add an HBF stack and extend the interposer to cope with that as well as the HBM. Then there needs to be a memory controller that moves data as required between the VRAM HBM and HBF components. The resulting system would look like this:
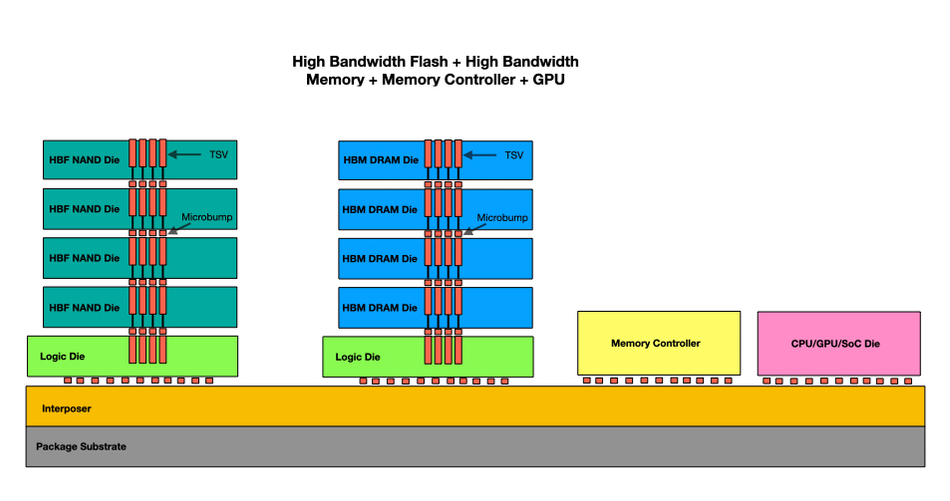
There is no CPU DRAM or SSD involved here. As we understand it, a GPU server using an HBF system would require custom designs tailored to each GPU vendor and product family. This is not a plug-and-play system and the engineering cost would be higher. The payoff would be much higher memory capacity and speed than that possible with an aiDAPTIV+ system. The data in the VRAM would always be much closer to the GPU than with Phison’s scheme, providing lower latency and higher bandwidth.
Think of Phison’s aiDAPTIV concept as enabling smaller GPUs to act like bigger ones with more memory, putting AI training in reach of medium-sized businesses and small-scale edge systems. Sandisk’s HBF enables large GPU servers, hamstrung by memory limitations, to train the largest models by expanding their memory capacity to a high degree.
The Phison and Sandisk technologies are different horses for different courses and can co-exist.





