


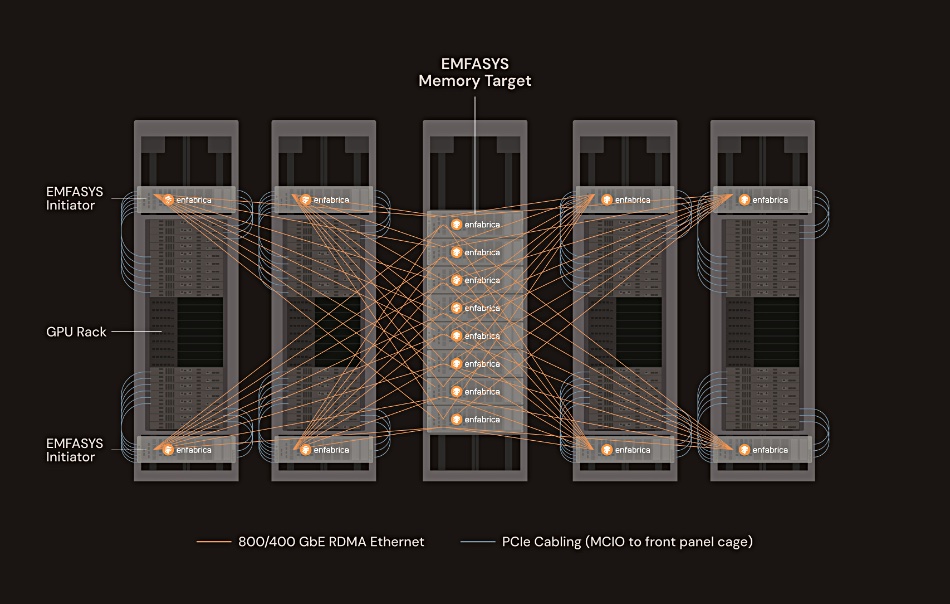
Enfabrica EMFASYS technology brings Ethernet RDMA and CXL together to produce a memory appliance that can be connected to AI GPU server compute racks with the aim of providing elastic memory bandwidth and capacity, offloading the GPU’s high-bandwidth memory (HBM).
The memory appliance is connected to the GPU servers with a 3.2 Tbps ACF-S SuperNIC switch, which combines PCIe/CXL and Ethernet fabrics to interconnect GPUs and accelerators with multi-port 800 GbE connectivity. The core of the switch is an ACF-S chip providing 800 and 400 GbE interfaces, a high radix of 32 network ports, and 160 PCIe lanes. It supports 144 CXL 2.0 lanes with up to 18 TB of pooled DDR5 memory.
Enfabrica CEO Rochan Sankar stated: “AI inference has a memory bandwidth scaling problem and a memory margin stacking problem. As inference gets more agentic versus conversational, more retentive versus forgetful, the current ways of scaling memory access won’t hold. We built EMFASYS to create an elastic, rack-scale AI memory fabric and solve these challenges in a way that hasn’t been done before. Customers are excited to partner with us to build a far more scalable memory movement architecture for their GenAI workloads and drive even better token economics.”
Enfabrica was founded by Sankar and chief development officer Shrijeet Mukherjee in 2019. Its known funding starts with a $50 million A-round in 2022. A B-round raised $125 million in June 2023, and a C-round pulled in $115 million in November last year, taking the total raised to $290 million.
In a sense, the market has come to Enfabrica as generative AI has only exploded in popularity in the last couple of years. The company says generative, agentic, and reasoning-driven AI workloads are growing exponentially – in many cases requiring 10 to 100 times more compute per query than previous large language model (LLM) deployments and accounting for billions of batched inference calls per day across AI clouds.
Unless GPU memory (HBM) is kept loaded, the very expensive GPUs fall idle and waste the dollars it cost to buy the GPU servers equipped with them. Enfabrica claims its technology addresses the need for AI clouds to extract the highest possible utilization of GPU and HBM resources while scaling to greater user/agent count, accumulated context, and token volumes.

The ACF-S switch enables the striping of memory transactions across a wide number of memory channels and Ethernet ports. We’re told it delivers read access times in microseconds and a software-enabled caching hierarchy hides transfer latency within AI inference pipelines. Features include high-throughput, zero-copy, direct data placement and steering across a four or eight-GPU server complex, or alternatively across 18-plus channels of CXL-enabled DDR memory. Its remote memory software stack based on InfiniBand Verbs enables massively parallel, bandwidth-aggregated memory transfers between GPU servers and commodity DRAM over bundles of 400/800 GbE network ports.
Enfabrica claims it is no longer necessary to buy more GPUs to get more HBM capacity. The pitch is: use its switch to bulk up DRAM instead and make better use of the GPUs you already have. The switch is claimed to outperform flash-based inference storage alternatives with 100x lower latency and unlimited write/erase transactions. Enfabrica said that “scaling memory with EMFASYS alleviates the tax of linearly growing GPU HBM and CPU DRAM resources within the AI server based on inference service scale requirements alone.”
HBM offload to DRAM then NAND is provided by Phison’s aiDAPTIV+ software but this does not use Ethernet RDMA nor CXL and is thus a relatively slow technology compared to EMFASYS.
Enfabrica is an active advisory member of the Ultra Ethernet Consortium (UEC) and a contributor to the Ultra Accelerator Link (UALink) Consortium.
Both the EMFASYS AI memory fabric system and the 3.2 Tbps ACF SuperNIC chip are currently sampling and piloting with customers. Get more information here, particularly concerning the ACF SuperNIC silicon, system, and host software.





